Method
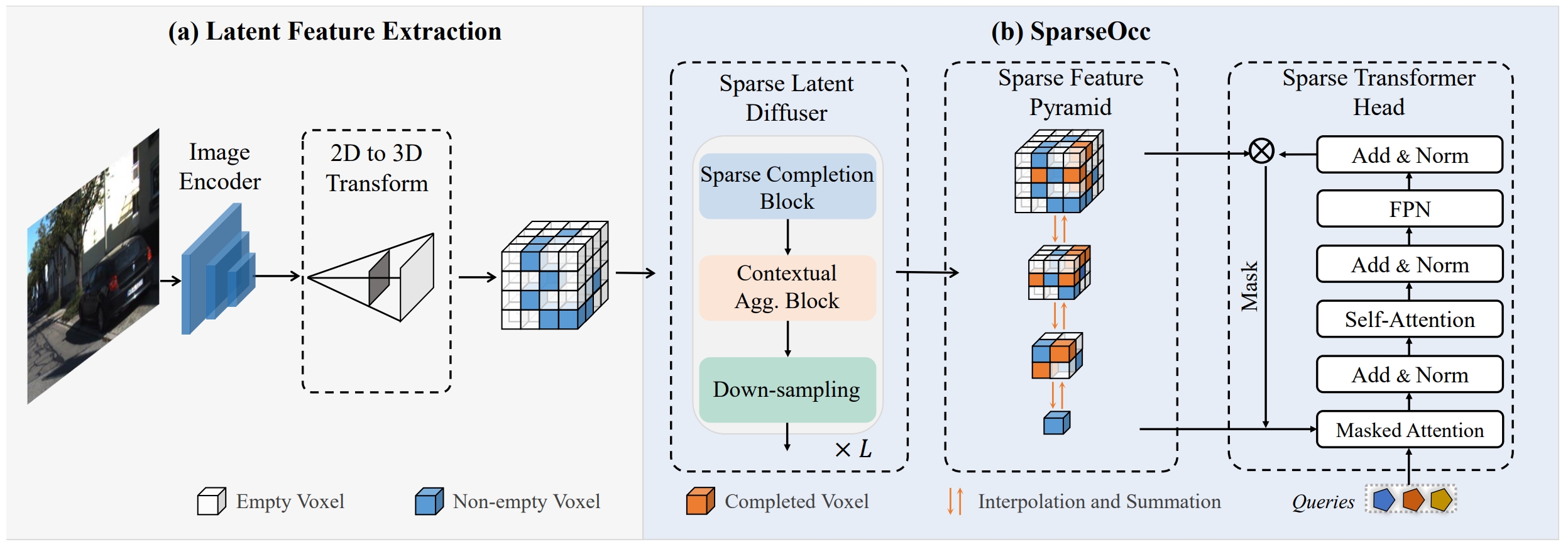
Images captured by monocular or surrounding cameras are first passed to a 2D encoder, yielding 2D latent features. Then the latent features are mapped to 3D using the predicted depth map following the LSS. SparseOcc adopts a sparse representation for the latent space. Upon this representation, we introduce three key building blocks: a latent diffuser that performs completion, a feature pyramid that enhances receptive filed, and a transformer head that predicts semantic occupancy.
Experiments
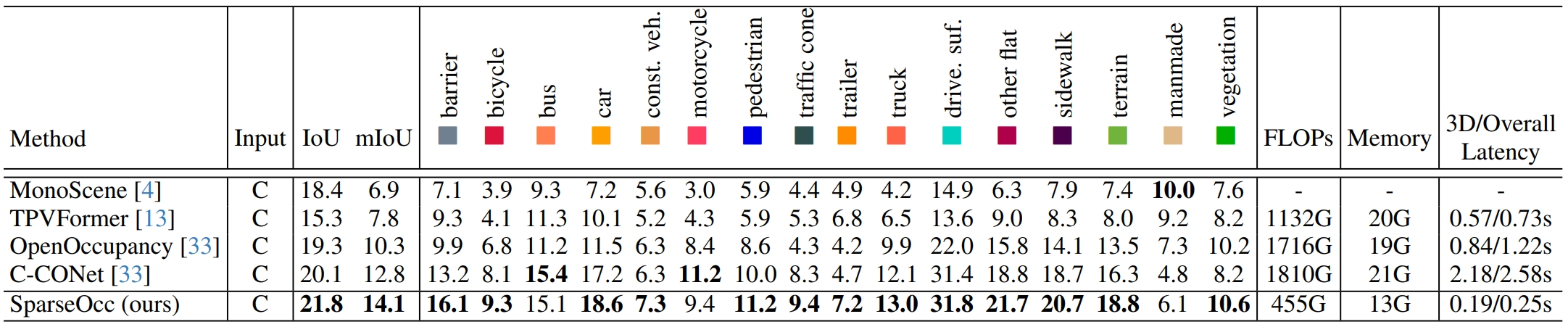
Semantic occpancy prediction results on nuScenes-Occupancy validation set. For accuracy evaluation, We report the geometric metric IoU, semantic metric mIoU, and the IoU for each semantic class. For efficiency evaluation, we report the FLOPs, training GPU memory, and 3D/overall inference latency. The C denotes camera and the bold numbers indicate the best results.
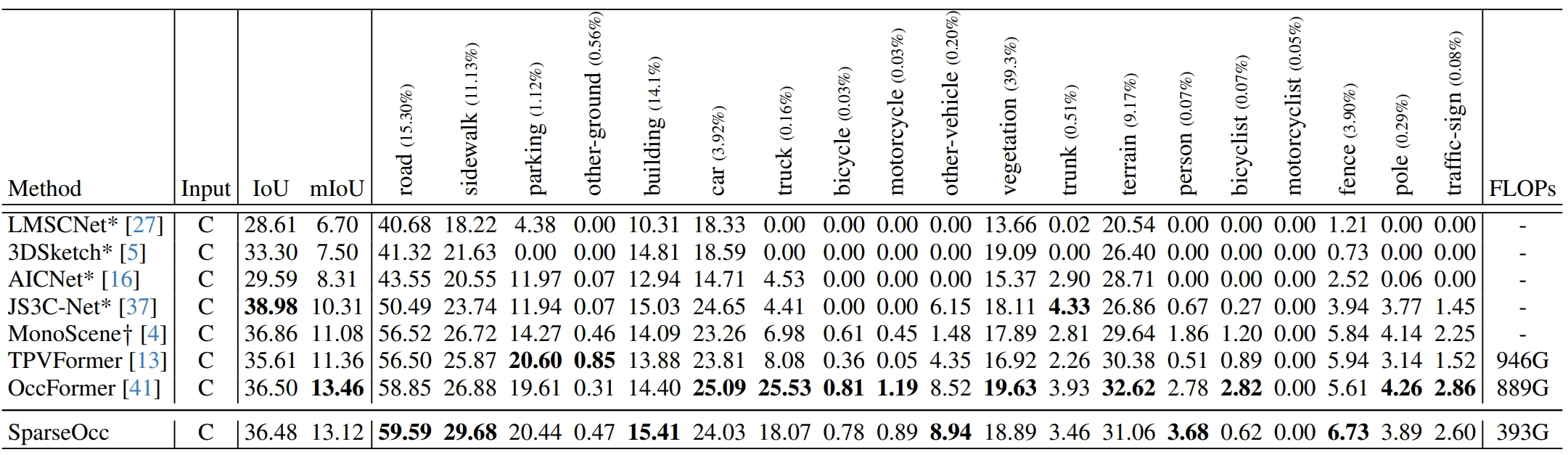
Semantic scene completion results on SemanticKITTI validation set. For accuracy evaluation, We report the geometric metric IoU, semantic metric mIoU, and the IoU for each semantic class. For efficiency evaluation, we report the FLOPs. The C denotes camera and the bold numbers indicate the best results. The methods with “*” are RGB-input variants reported by for fair comparison.
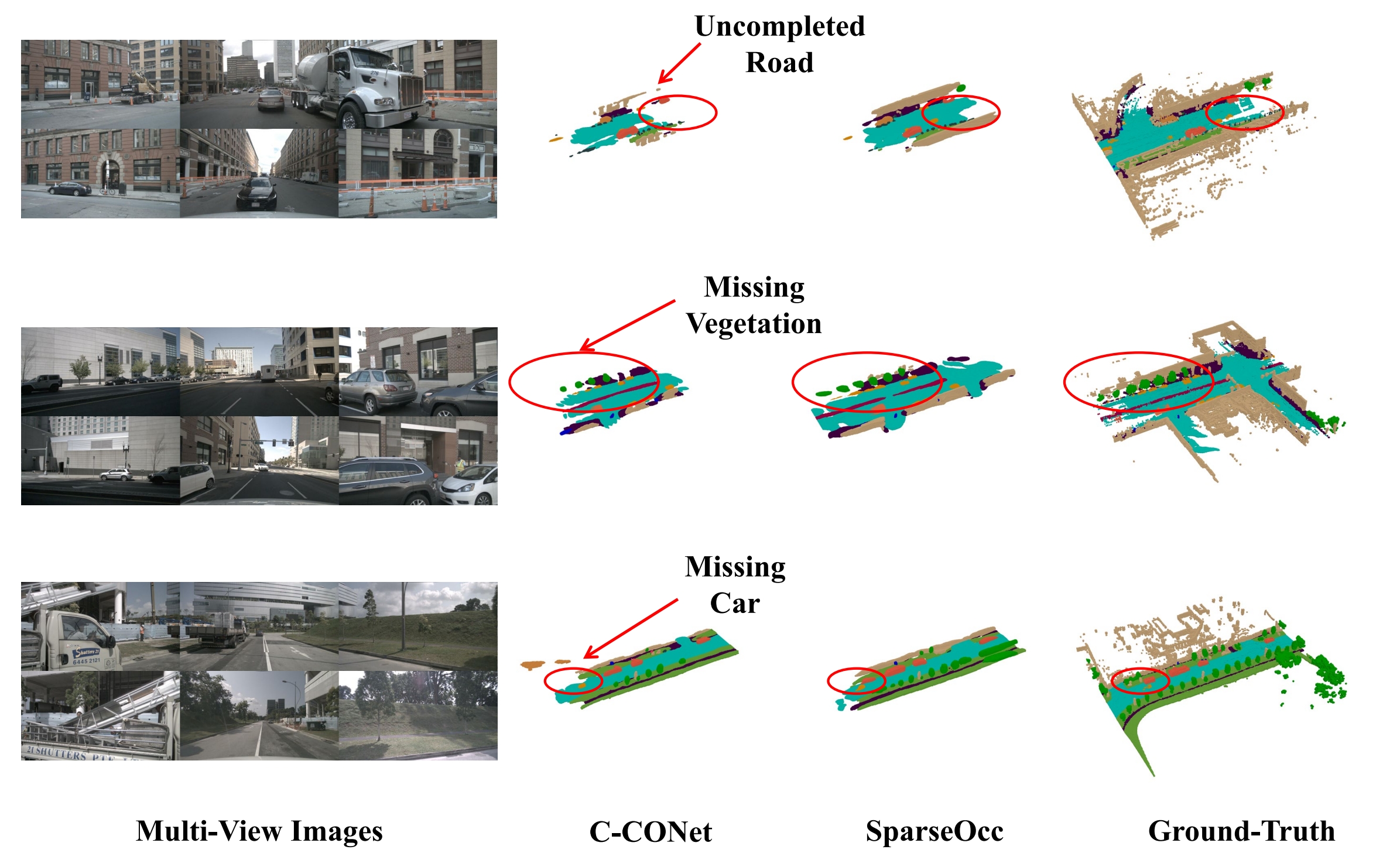
Qualitative results of 3D semantic occupancy on nuScenes-Occupancy validation set. The input multi-view images are shown on the leftmost and the occupancy predictions of C-CONet, our SparseOcc, and the ground-truth are then visualized sequentially. Compared to 3D dense representation based C-CONet, our SparseOcc achieves better completion and segmentation as highlighted by the red circles.
BibTeX
@inproceedings{tang2024sparseocc,
title = {SparseOcc: Rethinking Sparse Latent Representation for Vision-Based Semantic Occupancy Prediction},
author = {Tang, Pin and Wang, Zhongdao and Wang, Guoqing and Zheng, Jilai and Ren, Xiangxuan and Feng, Bailan and Ma, Chao},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year = {2024}
}